Using QSVT for Matrix Inversion
This notebook uses the Quantum Singular Value Transformation (QSVT) algorithm to solve the problem of matrix inversion. The demo is based on the Grand unification of quantum algorithms paper.
Problem Encoding
We start by defining a specific problem. We can take a matrix that is not symmetric, in comparison to the HHL algorithm.
We encode \(A\) in a larger unitary matrix. For simplicity, we just sample a random unitary U_a and take its first block as \(A\).
import numpy as np
import scipy
# the size of the unitary which block encodes A
REG_SIZE = 3
def get_random_unitary(num_qubits, seed=4):
np.random.seed(seed)
X = np.random.rand(2**num_qubits, 2**num_qubits)
U, s, V = np.linalg.svd(X)
return U @ V.T
U_a = get_random_unitary(REG_SIZE)
A_dim = int(U_a.shape[0] / 2)
A = U_a[:A_dim, :A_dim]
print(A)
[[-0.05338002 -0.36103662 -0.54016489 -0.39026125]
[-0.33304121 0.10648228 0.37346704 -0.33977916]
[ 0.4167817 -0.75180519 0.17593867 0.20944773]
[ 0.26891079 -0.05333795 -0.32668787 -0.33602829]]
Make sure the singular values for A are smaller than 1:
assert not (np.linalg.svd(A)[1] > 1).sum()
b = np.arange(A_dim)
b = b / np.linalg.norm(b)
print(b)
[0. 0.26726124 0.53452248 0.80178373]
Verify \(U_{a}\) is indeed unitary
assert np.allclose(U_a @ U_a.T, np.eye(U_a.shape[0]), rtol=1e-5, atol=1e-6)
Calculate the condition number \(\kappa=max(\frac{1}{\sigma_i})\):
kappa = max(1 / np.linalg.svd(A)[1])
print(kappa)
3.459862838470858
np.linalg.svd(A)[1]
array([0.99132079, 0.84978294, 0.52403662, 0.2890288 ])
Now for the Quantum Part!

Defining the QSVT Circuit for the Problem
We start with the general QSVT framework definition. It accepts a unitary that block-encodes a matrix together with projector-controlled-cnot functions, which identify the block in which the matrix is encoded.
It applies the qsvt_step multiple times, iterating over the rotation angles provided that encode the polynomial transformation.
Note that the last step is quite tricky and depends on the specific transformation we wish to perform. Here the code is suitable for the matrix-inversion case. In addition, we wrap the auxilliary qubit with \(H\) gates.
from classiq import *
from classiq.qmod.symbolic import floor
@qfunc
def my_projector_controlled_phase(
phase: CReal,
proj_cnot: QCallable[Const[QArray], Permutable[QBit]],
state: QArray,
aux: QBit,
) -> None:
within_apply(lambda: proj_cnot(state, aux), lambda: RZ(phase, aux))
@qfunc
def my_qsvt_step(
phase1: CReal,
phase2: CReal,
proj_cnot_1: QCallable[Const[QArray], Permutable[QBit]],
proj_cnot_2: QCallable[Const[QArray], Permutable[QBit]],
u: QCallable[QArray],
state: QArray,
aux: QBit,
):
u(state)
my_projector_controlled_phase(phase1, proj_cnot_2, state, aux)
invert(lambda: u(state))
my_projector_controlled_phase(phase2, proj_cnot_1, state, aux)
@qfunc
def my_qsvt(
phase_seq: CArray[CReal],
proj_cnot_1: QCallable[Const[QArray], Permutable[QBit]],
proj_cnot_2: QCallable[Const[QArray], Permutable[QBit]],
u: QCallable[QArray],
state: QArray,
aux: QBit,
) -> None:
H(aux)
my_projector_controlled_phase(phase_seq[0], proj_cnot_1, state, aux)
repeat(
count=floor((phase_seq.len - 1) / 2),
iteration=lambda index: my_qsvt_step(
phase_seq[2 * index + 1],
phase_seq[2 * index + 2],
proj_cnot_1,
proj_cnot_2,
u,
state,
aux,
),
)
if_(
condition=phase_seq.len % 2 == 1,
then=lambda: IDENTITY(state),
else_=lambda: (
u(state),
my_projector_controlled_phase(
phase_seq[phase_seq.len - 1],
proj_cnot_2,
state,
aux,
),
),
)
H(aux)
Matrix Inversion Logic
We define the specific use case of the matrix inversion. In this case, both projectors are the same, and we expect the block-encoded matrix to apply on the states where the first qubit value is \(|0\rangle\):
class QsvtState(QStruct):
state: QNum[REG_SIZE - 1, UNSIGNED, 0]
block: QBit
@qfunc
def my_qsvt_inversion(
phase_seq: CArray[CReal],
u: QCallable[QArray],
qsvt_state: QsvtState,
aux: QBit,
) -> None:
@qfunc
def _projector_cnot(qsvt_state: Const[QsvtState], aux: Permutable[QBit]):
aux ^= qsvt_state.block == 0
my_qsvt(
phase_seq,
lambda state, aux: _projector_cnot(state, aux),
lambda state, aux: _projector_cnot(state, aux),
u,
qsvt_state,
aux,
)
Getting the Phase Sequence for the Inverse Function
Get the coefficient of the sign function directly, based on the ERFC approximation, using the pyqsp package:
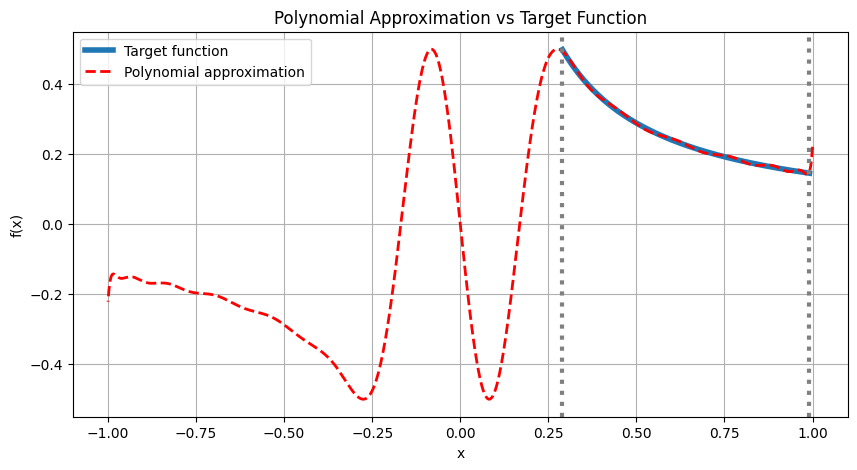
We first find a polynomial approximation to the \(\frac{1}{x}\) function. Notice that the function is exploding as \(x\) goes to 0, which breaks the rules for the existence of QSP polynomial. However, we can limit the polynomial to approximate only at the range between \([\sigma_{min}, \sigma_{max}]\), where \(\sigma_{min}, \sigma_{max}\) are the smallest and largest eigenvalues of the block encoding, respectively. We normalize the polynomial such that \(P(\sigma_{min})\approx 1\). Also, we make sure that the polynomial is bounded by 1 in the entire range \([-1, 1]\).
The following is a code for finding such a polynomial approximation on the mentioned interval. To be general to all matrix types, we use odd polynomial:
import cvxpy as cp
import matplotlib.pyplot as plt
def optimize_inversion_polynomial(w_min, w_max, degree, M=1000, plot=True):
# Discretize [-1, 1] using M grid points (interpolants)
xj_full = np.cos(np.pi * np.arange(M) / (M - 1)) # Chebyshev nodes on [-1, 1]
# Select grid points for the objective in [w_min, w_max]
xj_obj = xj_full[(xj_full >= w_min) & (xj_full <= w_max)]
# Define the Chebyshev polynomials of odd degrees
k_max = (degree - 1) // 2
T_matrix_full = np.array(
[
[np.cos((2 * k + 1) * np.arccos(x)) for k in range(k_max + 1)]
for x in xj_full
]
)
T_matrix_obj = np.array(
[[np.cos((2 * k + 1) * np.arccos(x)) for k in range(k_max + 1)] for x in xj_obj]
)
# Define optimization variables
c = cp.Variable(k_max + 1) # Coefficients for Chebyshev polynomials
F_values_full = T_matrix_full @ c # Values for constraints
F_values_obj = T_matrix_obj @ c # Values for the objective function
# Relaxed constraint
scale = 0.5
def target_function(x):
return scale * (w_min) / x
# Define the optimization problem
objective = cp.Minimize(cp.max(cp.abs(F_values_obj - target_function(xj_obj))))
constraints = [cp.abs(F_values_full) <= scale]
prob = cp.Problem(objective, constraints)
# Solve the optimization problem
prob.solve()
print(f"Max error value: {prob.value}")
# Return coefficients, optimal value, and grid points
pcoefs = np.zeros(len(c.value) * 2)
pcoefs[1::2] = c.value
if plot:
y_target = target_function(xj_obj)
y_approx = np.polynomial.Chebyshev(pcoefs)(xj_full)
# Plot
plt.figure(figsize=(10, 5))
plt.plot(xj_obj, y_target, label="Target function", linewidth=4)
plt.plot(
xj_full,
y_approx,
"--",
label="Polynomial approximation",
linewidth=2,
c="r",
)
plt.title("Polynomial Approximation vs Target Function")
plt.xlabel("x")
plt.ylabel("f(x)")
# Draw vertical lines
plt.axvline(w_min, color="gray", linestyle=":", linewidth=3)
plt.axvline(w_max, color="gray", linestyle=":", linewidth=3)
plt.legend()
plt.grid(True)
plt.show()
return pcoefs, scale
svd = np.linalg.svd(A)[1]
pcoefs, scale = optimize_inversion_polynomial(min(svd), max(svd), degree=30)
Max error value: 0.004700998285219804
import numpy as np
import pyqsp
from pyqsp.angle_sequence import Polynomial, QuantumSignalProcessingPhases
ang_seq = QuantumSignalProcessingPhases(
pcoefs, signal_operator="Wx", method="laurent", measurement="x"
)
pyqsp.response.PlotQSPResponse(ang_seq, signal_operator="Wx", measurement="x")
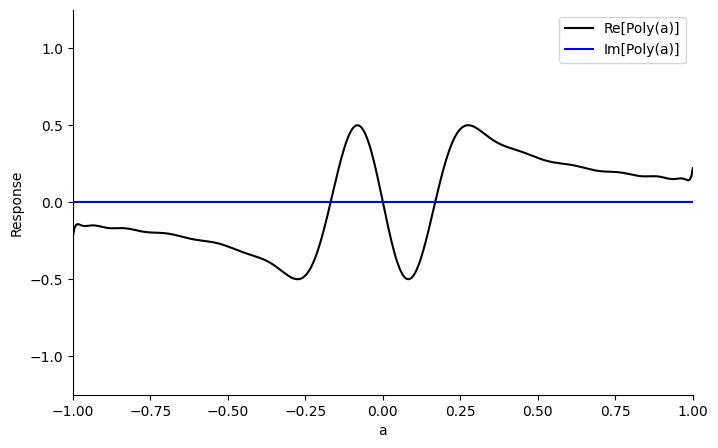
Adjusting Phase Conventions
The conventions by which the pyqsp package calculates the the phases are different from the phases we need for this QSVT circuit. The following block takes care of them.
As \(R(a)=-i*e^{i\frac{\pi}{4}Z}W(a)e^{i\frac{\pi}{4}Z}\) and we have an odd number of rotations, we get an i phase for our polynomial, so we get \(Im(P(a))\) instead of the real part. We receive the result in the \(|1\rangle\) state in the ancilla, which can be fixed by adding a \(\pi/2\) phase to the last or first rotation.
# change the R(x) to W(x), as the phases are in the W(x) conventions
phases = np.array(ang_seq)
phases[1:-1] = phases[1:-1] - np.pi / 2
phases[0] = phases[0] - np.pi / 4
phases[-1] = phases[-1] + (2 * (len(phases) - 1) - 1) * np.pi / 4
# verify conventions. minus is due to exp(-i*phi*z) in qsvt in comparison to qsp
phases = -2 * phases
Using the Inversion Function to Solve a Linear System
The following block defines the main function. This is the entry point for the quantum algorithm, which brings all the previous parts together.
Specifically, we use the prepare_amplitudes function to load the \(b\) vector into the quantum state. We then apply 'qsvt_inversion`. We use the dagger of the unitary \(U\) that block-encodes \(A\), because, using the SVD decomposition:
@qfunc
def main(
qsvt_state: Output[QsvtState],
aux: Output[QBit],
) -> None:
allocate(qsvt_state)
inplace_prepare_amplitudes(b.tolist(), 0, qsvt_state.state)
allocate(aux)
my_qsvt_inversion(
phase_seq=list(phases),
u=lambda arg0: unitary(
# Here we can just use the transpose of A as is it real valued
elements=U_a.T.tolist(),
target=arg0,
),
qsvt_state=qsvt_state,
aux=aux,
)
Synthesizing and Executing the Circuit Using a State Vector Simulator
We want to get \(x=A^{-1}b\):
# convert the functions to a qmod model
qmod = create_model(main, preferences=Preferences(optimization_level=0))
# we will want to execute this qmod on a state-vector simulator:
execution_preferences = ExecutionPreferences(
num_shots=1,
backend_preferences=ClassiqBackendPreferences(
backend_name=ClassiqSimulatorBackendNames.SIMULATOR_STATEVECTOR
),
)
qmod = set_execution_preferences(qmod, execution_preferences)
write_qmod(qmod, name="qsvt_matrix_inversion", decimal_precision=15)
We synthesize the model into a quantum program:
qprog = synthesize(qmod)
show(qprog)
Quantum program link: https://platform.classiq.io/circuit/2yfk8LWFMgPAyb2N9FQBR9bQoyE
We execute it on the simulator:
result = execute(qprog).result_value()
Postprocessing
We are interested in the projection of the state vector on the states where both the auxilliary qubit and the block qubit are \(|0\rangle\):
def parse_results(result):
parsed_state_vector = result.parsed_state_vector
d = {
int(p.state["qsvt_state"]["state"]): p.amplitude
for p in parsed_state_vector
if p.state["aux"] == 0 and p.state["qsvt_state"]["block"] == 0
}
values = np.array([d[i] for i in range(len(d))])
global_phase = np.angle(values)[0]
values = np.real(values / np.exp(1j * global_phase))
return values
computed_x = parse_results(result)
print(computed_x)
[ 0.29004975 0.01914235 0.13097551 -0.24217925]
Let's compare it with the expected solution:
expected_x = scale / (kappa) * (np.linalg.inv(A) @ b)
print(expected_x)
assert np.allclose(computed_x, expected_x, atol=0.05)
[ 0.29134204 0.02176207 0.13386997 -0.24527315]
References
[1]: Martyn JM, Rossi ZM, Tan AK, Chuang IL. Grand unification of quantum algorithms. PRX Quantum. 2021 Dec 3;2(4):040203.