

View on GitHub
Open this notebook in GitHub to run it yourself
Quantum Algorithm
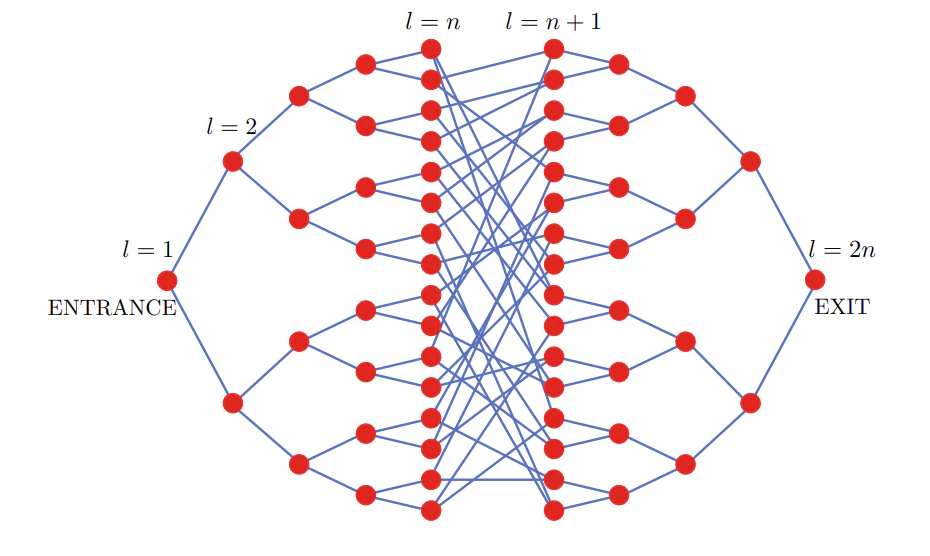
To model the columns of the glued trees structure as a system of coupled harmonic oscillators, we consider a matrix of size corresponding to the nodes of the glued trees structure, such that and is the number of columns of one of the two glued trees. This matrix is defined as , where is the adjacency matrix of the glued trees system using any ordering. For demonstration purposes, we use a simple linear ordering of this adjacency matrix such that the entrance node is first and the exit node is last. This matrix is symmetrical and takes the following shape:
nx.adjacency_matrix function to generate an adjacency matrix using that ordering. We decompose using Cholesky decomposition to get a square matrix where its product with its conjugate transpose is equal to .
This matrix is the same size as , however, so we must pad it with four columns of zeroes to get our matrix of size so has a size corresponding to a power of two. We can then create the block Hamiltonian with the proper size using and , and decompose it into a sum of Pauli strings using the Classiq built-in matrix_to_pauli_operator function.
The number of terms in the decomposition grows quickly with system size, and including all of them may produce circuits too deep for current quantum hardware. We therefore use two strategies depending on the system size.
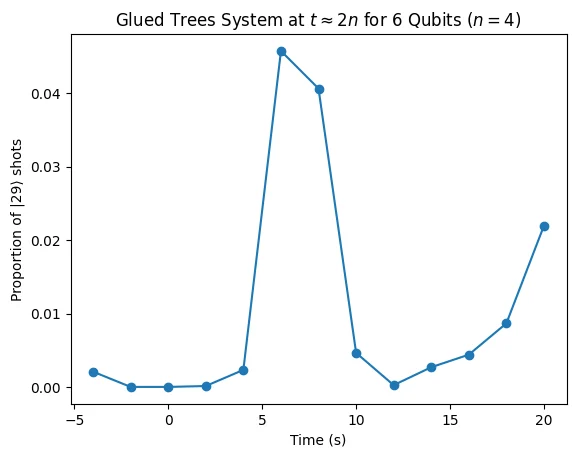
For a 6-qubit example (), the full Pauli decomposition yields only ~1088 terms, which is small enough to include all of them without truncation.
This gives a faithful Trotter approximation of the exact Hamiltonian.
For larger systems where truncation is necessary, the crop_pauli_list function selects the most representative terms using a diversity-weighted algorithm: 60% of the budget is filled by scanning qubit positions and selecting the largest-coefficient term for each Pauli type (, , , ) at each position; the remaining 40% are the highest-magnitude unused terms.
This balances broad structural coverage of the Hamiltonian with its most energetically significant contributions.
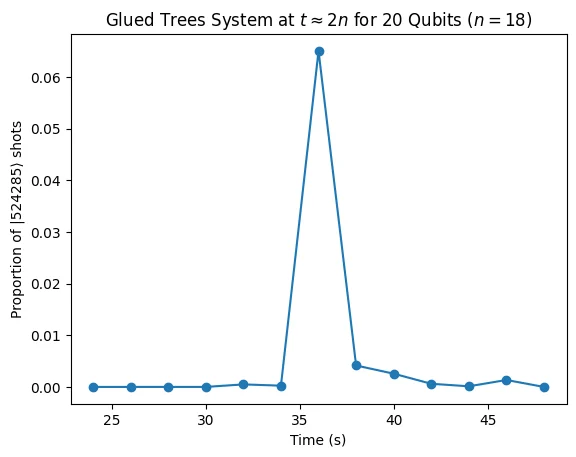
For the 20-qubit example (), the full Pauli decomposition is computationally infeasible. Instead, the Hamiltonian is approximated by a structured extension of the 12-qubit Pauli list: each term is padded to 20 qubits by replicating the second-highest-qubit Pauli operator across the inserted qubit positions, reflecting a pattern observed in the dominant Pauli strings of larger systems.
run_range.
This function takes the number of qubits and synthesizes a single parametric circuit that performs Hamiltonian simulation using the suzuki_trotter function.
The evolution time t is declared as a classical execution parameter (CReal), so the circuit is synthesized only once and then sampled at 13 different time values spanning in two-second intervals using sample.
The num_shots parameter is set to 8192 to give enough room for significant spikes in a state to be apparent, given the high number of total possible states.
The resulting quantum state can be written as follows:
where and using a linear ordering of nodes.
Since the speed of the entrance node oscillator is represented by the quantum state and should have probability 1 at , there is no specific state preparation necessary for this system. It should also be noted that since our matrix is padded with four rows of zeroes, the highest four quantum states do not correspond to the displacement or speed of any oscillator.
This means that the quantum state representing the speed of the exit node oscillator , which is what we are most interested in, corresponds to . We track this particular quantum state around , expecting a spike that represents the system of oscillators “reaching” the exit node from the initial push to the entrance node.
run_range for 6 qubits (), a small qubit size where the full Pauli decomposition has only ~1088 terms, making it feasible to include all of them without truncation (max_terms=None).
This gives a faithful Trotter simulation of the exact Hamiltonian.
The Pauli list is recalculated from scratch using a fixed random seed for reproducibility.
Output:
Output:
run_range for 20 qubits (), a qubit size that is still simulatable but whose Pauli list cannot be generated in reasonable time and is therefore approximated by padding the 12-qubit Pauli list.
This instance of the function takes a few minutes to run if the cached Pauli list is used.
Output:
Output:
graph_results function plots the proportion of shots for the qubit state corresponding to for a given qubit size from to :
sample.
Perhaps the most interesting thing about the glued trees algorithm is that it is a relatively heavy case of using a quantum computer to gain an exponential advantage, usually requiring several executions at different time points to observe the intended result, but it can still execute effectively on present-day quantum hardware due to the Pauli list cropping. Suggestion: Try out the algorithm on both a simulator and quantum hardware for various qubit sizes.