View on GitHub
Open this notebook in GitHub to run it yourself
What this notebook does
Quantum walks are often used as building blocks for graph exploration / graph-based quantum algorithms. This notebook simulates a discrete-time quantum walk on a complex network (graph).- The graph is a set of nodes connected by edges (we generate it with NetworkX).
- The walker position is stored in a quantum register
x. - A second register
yacts like a coin / direction / neighbor-choice register. - Each step of the walk applies:
- Coin operator (mix amplitudes in a way that depends on the current node’s neighbors)
- Shift operator (moves the walker according to the coin register)
Note: This is a discrete-time walk (coin + shift), not a continuous-time walk.
Imports and dependencies
Step 1 — Create a “complex network” (the graph)
Here we generate a small graphG.
The notebook currently uses a Watts–Strogatz model, which is a classic “small-world” network model:
- it has high clustering (like regular lattices),
- and short path lengths (like random graphs).
- Erdős–Rényi (random graph)
- Barabási–Albert (scale-free graph)
Step 2 — Decide how many qubits are needed for the position register
If the graph hasN nodes, we need enough qubits to encode node indices in binary.
N = len(G.nodes())num_qubits = ceil(log2(N))
x can represent 2**num_qubits = N.
Output:
Step 3 — Build “neighbor-aware” probability vectors
A quantum walk on a graph needs a way to represent “where can I go next from node ?”. We create helper functions:get_edges_of_node(G, i): returns the neighbors of nodei.inner_degree(G, num_qubits, i): builds a length2**num_qubitsvector where:- entries corresponding to neighbors of
iare1, - all others are
0, - then we normalize by the node degree
kto get a uniform distribution over neighbors.
- entries corresponding to neighbors of
y register so it represents “allowed moves” from the current node.
Step 4 — Define the quantum walk (state prep, coin, shift, and repeated steps)
This cell defines the core quantum logic using Classiq@qfunc.
Registers
x: position register (which node the walker is on)y: coin / neighbor register (encodes the neighbor-choice space)
4.1 Initial state: prepare_initial_state(x, y)
Goal: start with a clean, interpretable state.
- Prepare
xin a uniform superposition over valid nodes:
-
If
Nis exactly2**num_qubits, a Hadamard transform gives uniform superposition automatically. -
Otherwise, we prepare a custom probability vector that gives equal weight to nodes
0..N-1and zero to invalid states.
- Prepare
yconditioned on the current node inx: For each nodei, ifx == i, we prepareyusing the neighbor distribution vector frominner_degree(...).
- “uniform over nodes” in
x, - and for each node,
ycontains amplitudes only on its neighbors.
4.2 Coin operator: my_coin(x, y)
A discrete-time quantum walk needs a “coin flip” to mix amplitudes.
Here, the coin depends on the current node:
- If
x == i, apply a Grover diffuser on registerycorresponding to neighbors of nodei.
4.3 Shift operator: my_shift(x, y)
This updates the position based on the coin information.
4.4 Repeating steps: discrete_quantum_walk(time, coin, shift, x, y)
We apply the pair (coin, shift) repeatedly time times using power(time, ...).
That is exactly the discrete-time walk loop:
(coin → shift) × t
Step 5 — Choose number of steps, build main, and synthesize the circuit
Number of steps
t controls how far the quantum walk evolves.
More steps usually means:
- wider spreading over the graph,
- more interference patterns,
- sometimes more “structure” in the final distribution (depending on the graph).
The main quantum program
main(x: Output[QNum[num_qubits]]):
- Allocates
x(position) andy(coin). - Prepares the initial state.
- Applies the discrete-time quantum walk for
tsteps. - Drops
y(we only care about measuring the position distribution inx).
synthesize(main)compiles the high-level program into an executable quantum program.show(qprog)displays the synthesized result.
Output:
Output:
Step 6 — Execute and collect results
Here we run the synthesized program and fetch the results. The key output we care about is the measured distribution of the position registerx:
- each possible node index
xhas a probability, - these probabilities should sum to ~1 (up to sampling / execution effects).
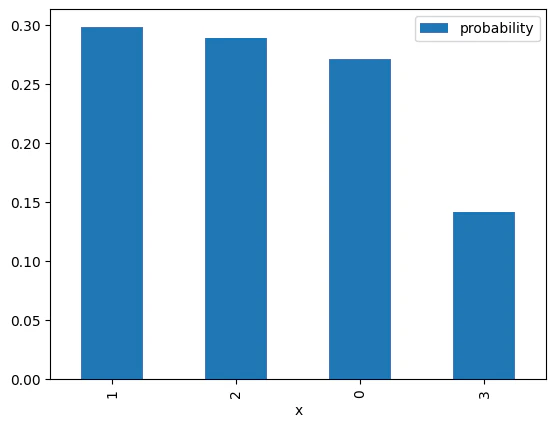
Step 7 — Visualize the probability distribution over nodes
We plot a bar chart:- x-axis: node index (the measured value of the position register
x) - y-axis: probability of measuring that node
- Compare “high-probability nodes” to the graph drawing.
- Try changing the graph model or
tand see how the distribution changes.
Output:
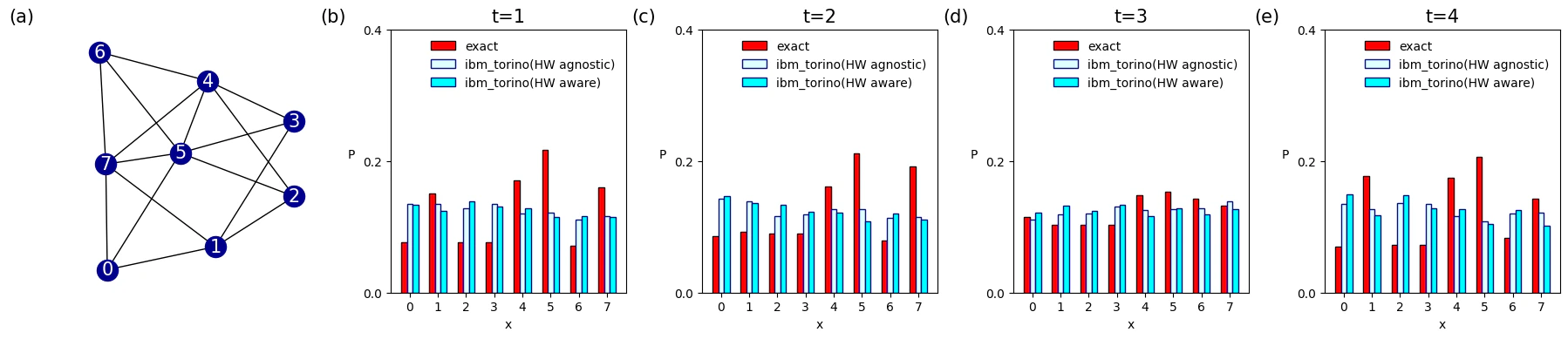
(Optional) Hardware-Aware Synthesis and Hardware Execution
In this notebook, we executed the circuit on theibm_torino processor.
The Classiq platform allows specifying a particular processor through ExecutionPreferences.
Before executing on quantum hardware, you can perform synthesis that incorporates hardware-specific constraints by configuring the preference settings.
The following command runs hardware-aware synthesis to optimize your circuit for a target device.
For more details, refer to the Hardware-Aware Synthesis.
ExecutionPreferences class allows you to define parameters such as the number of shots and backend-specific credentials.
The following code demonstrates how to set up an execution session for an IBM Quantum backend:
Result
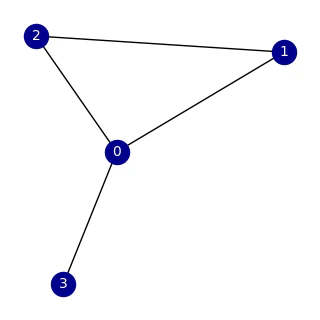
Once the graph structure is defined, you can perform a quantum spatial search to find a specific node. In this example, the search is conducted on a Watts-Strogatz small-world graph, which is generated using the NetworkX library to create a complex network topology. Below data is quantum spatial search on
G = nx.connected_watts_strogatz_graph(n=4, k=2, p=0.2, tries=100, seed=312) .
Below data is quantum spatial search on
G = nx.connected_watts_strogatz_graph(n=8, k=4, p=0.2, tries=100, seed=312) .
Vizualization