

View on GitHub
Open this notebook in GitHub to run it yourself
Hamiltonian encoding
The optimization objective function is encoded into a Hamiltonian function formulated as a weighted sum of Pauli strings: with each pauli string, , composed of a Pauli operation () applied to each of the qubits in the register. For example, , applies a Pauli to the first qubit and a Pauli to the fourth qubit The encoding of the objective start by defining the function with binary variables, , and then defining Pauli strings with corresponding to the original variables. If the objective variables’ domain is , a transformation is used: (commonly referred to as spin to bit transformation) Since the encoding results in Pauli strings composed only of , and , the Pauli string is called diagonal, this has the following benefits:- Easy exponentiation - the exponentiation results in simple to implement single or multi-qubit Z rotations
- No superposition mixing - the diagonal Hamiltonian does not create entanglement or rotate between basis states, enabling computation basis measurement
- Efficient measurement - all strings commute, allowing for a single simultaneous measurement of all strings
QMod tip
In the following cell the variableh is set to a diagonal hamiltonian using a self explanatory syntax that sums sparse Pauli strings, that is only the non identity Paulis are specified.
For example the first line, - 0.1247375 * Pauli.Z(0) * Pauli.Z(1) creates the string ZZIII with the weight -0.1247375.
The length of the string, is inferred from the largest qubit index in the sum.
The resulating variable has the type SparsePauliOp
For the optimization function a dual-use function is used for the Hamiltonian.
This function takes a argument that can be either a QArray or a list[int].
This allows the same function to be used both to:
- compute the cost expectation on the measurement results which are binary numbers ()
- create a quantum observable in the circuit, resulting in quantum gates
cost_func function negates the hamiltonian function since the problem involves finding the maximum value, but the optimization procedure (scipy.optimize.minimize) performs a minimization
The Cost Layer
As mentioned above, since the Hamiltonian is diagonal, its exponentiation is straightforward and amounts to phase addition due to Z rotations.This is accomplished with the phase function, which results in an efficient quantum implementation of .
The Mixer Layer
The QAOA mixer is defined as , and its exponentiaion is simply a rotation of the same angle () on all the qubitsThe QAOA Ansatz
The parametric QAOA ansatz is composed of pairs of exponentiated Mixer and Cost Hamiltonians:Assemble the full QAOA algorithm
We select layers for the QAOA. The quantum program takes the parameters as a single list (because thescipy.optimize.minimize function manipulate a 1-D array of parameters), and the quantum register of the qubits.
The qubits are initialized to , with a hadamard_transform and then the qaoa_ansatz, , is applied
Output:
Classical Optimization - “Vanilla” QAOA
The , and parameters are tuned until the objective function converges. The results of the parameters, and the solution vector are shown belowOutput:
Output:
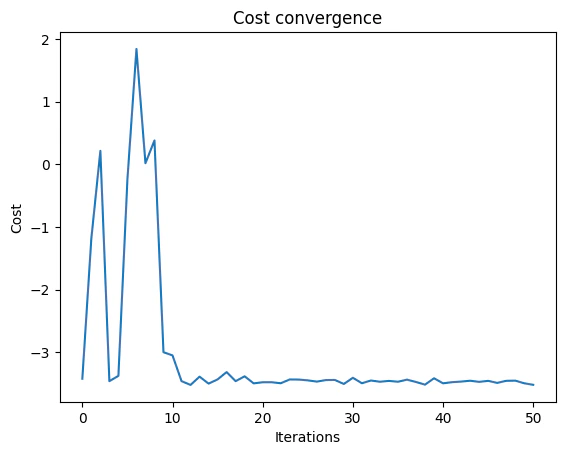
Displaying and Discussing the Results
Output:
ADAPT QAOA
The algorithm, based on the paper An adaptive quantum approximate optimization algorithm for solving combinatorial problems on a quantum computer, modifies QAOA by using different mixer layers, instead of the original . The algorithm defines a pool of potential mixer layers, that are simple to implement, and can match the problem better. The motiviation to the algorithm is rooted in t STA (shortcut to adiabaticity), with the hope of achieving better convergence than the “vanilla” QAOA. The algorithm proceeds incrementally:- initially, a single mixer layer is used (the original ) and the parameters are optimized
- all the potential mixer layers, , are tested as candidates.
- the mixer layer with the largest gradient is selected, the circuit grows by one layer, and the process continues (optimizing parameters and checking gradients)
- the process terminates when the scaled norm of the gradient vector drops below a threshold
Utilities
The following functions define some convenience utilities for computing the commutation of Pauli stringsThe Mixer Pool
The pool includes the default sum-of-X layer, as well as a sum-of-Y layer, followed by several single qubit layers with X and Y Paulis, and some two-qubit gates that add entanglement at the cost of a slightly more complicated layer. Several heuristics are suggested for building mixer pools based on the problem definition. A larger pool has a potential to find more efficient circuits, at the cost of computing many mixer gradients at each iterationes execution session and the params, and measuring the commutation of the mixer with the Hamiltonian:
Classical Optimization
- ADAPT QAOA
- The
ansatz mixerslist is incrementally populated with mixer layers, and used in the ansatz - Following each convergence, the gradients of all mixers are computed, and either a new mixer is added, or the adaptive process concludes
QMod tip
Since the mixer is no longer a sum of single bit Pauli strings (the default mixer can be written as: ), the exponent is not a trivial Pauli rotation (applying to each qubit) and the exponentiation has to be computed. An efficient and simple construct is the suzuki_trotter function that exponentiates aSparsePauliOp (a weighted sum of Pauli strings) with a given coefficient.
The adaptive_mixer_layer function uses this construct: suzuki_trotter(ansatz_mixers[mixer_idx], beta, 1, 1, qba), where the third and fourth arguments (1,1) specify the order and number of repetitions of the trotterization, which can be safely set to for simple Pauli strings.
Another variant is the multi_suzuki_trotter function that exponentiates a sum of Hamiltonians:
Output:
Output:
Output:
Output:
Output:
Output:
Output: