View on GitHub
Open this notebook in GitHub to run it yourself
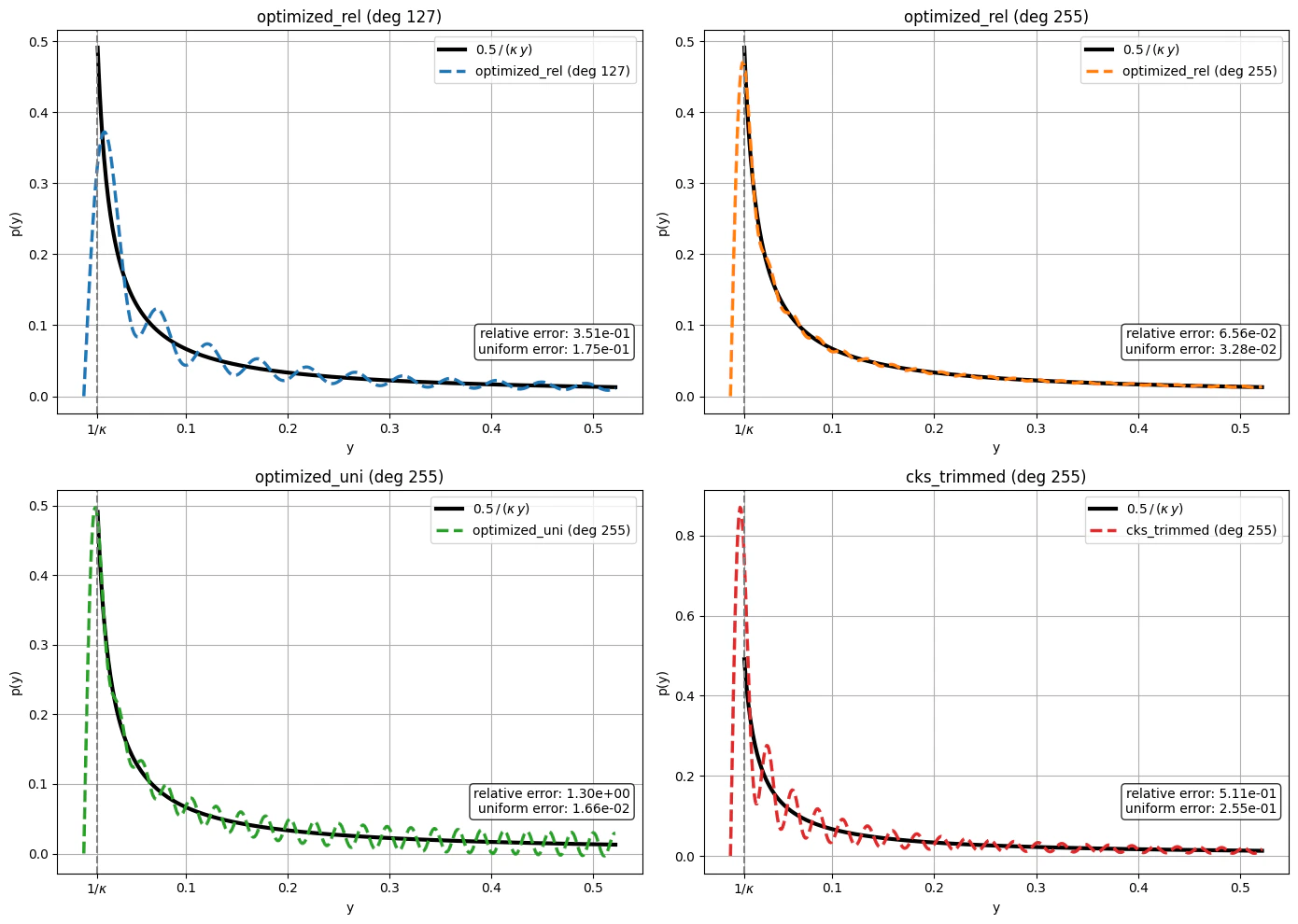
- Optimized relative error (
optimized_rel): the polynomial minimizing
- Optimized uniform error (
optimized_uni): the polynomial minimizing
- CKS trimmed (
cks_trimmed): polynomial approximation of the inverse function from the original CKS paper [1], trimmed to the target degree.
poly_inversion function).
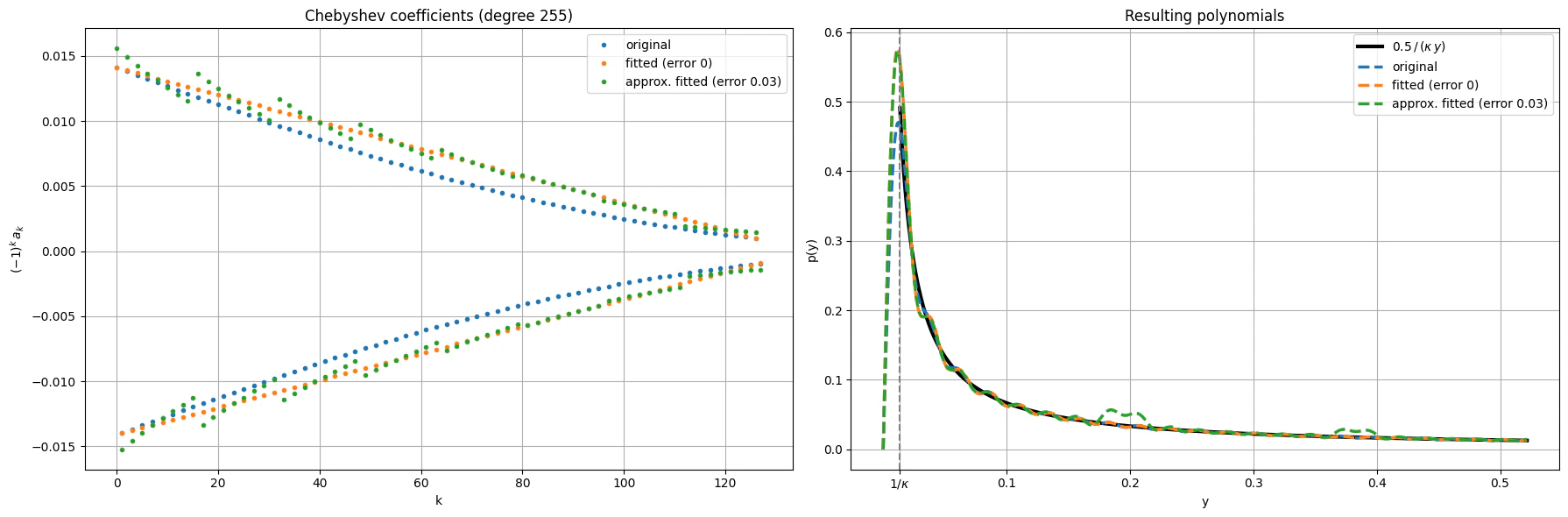
In addition, we consider an approximated transformation, perturbing the polynomial coefficients of those theoretical expansions.
This is relevant for reducing gate count in Approximated Chebyshev-LCU quantum linear solvers.
Chebyshev polynomials expansions for different types of error bound definitions
We upload some matrix, and consider its block-encoding. We need the block-encoding scaling factor in order to calculate the effective spectral range of singular-values.Output:
Output:
Chebyshev polynomials expansions with non-exact coefficients
We obtain the approximated coefficients loaded by approximate state preparation. This block enters as the PREPARE part in the Chebyshev-LCU approach.Output:
Output:
Output:
Output:
Output:
Output: