Use this file to discover all available pages before exploring further.
View on GitHub
Open this notebook in GitHub to run it yourself
Quantum Matrix Inversion (or Quantum Linear Solver) via QSVT provides a framework for solving linear systems exponentially faster than known classical methods under certain conditions [1]. The algorithm employs a polynomial transformation of singular values to block-encode the inverse of a matrix, which can then be applied on a prepared quantum state to solve a linear equation. Given an efficient routine to embed the classical matrix as a quantum function (block-encoding), this algorithm gives a clean and optimal way to implement matrix inversion compared to other quantum methods. Quantum linear solvers based on block-encoding have many applications, e.g., in Plasma Physics and Fluid Dynamics.
Input: An N×N matrix A with condition number κ (the ratio between the maximal and minimal singular values), and a vector ∣b⟩ prepared as a quantum state.
Promise: The matrix A is well-conditioned (invertible, with bounded spectrum) and can be efficiently block-encoded in a unitary UA (see technical note at the end of this demo).
Output: A quantum state proportional to ∣x⟩=A−1∣b⟩, encoding the solution of the linear system Ax=b.
Complexity: Using QSVT, matrix inversion requires O(κlog(κ/ϵ)) queries of the block-encoding unitary, where ϵ is the precision parameter. Typically, an efficient block-encoding scales as poly(logN), resulting in an overall O~(κpolylog(N,1/ϵ)) complexity for the QSVT linear solver. This improves exponentially in ϵ upon the original Harrow–Hassidim–Lloyd (HHL) algorithm, and exponentially in N compared to classical linear solvers, while matching known lower bounds for quantum linear solvers [2].(As with all quantum linear solvers, extracting the full solution state ∣x⟩ removes the speedup; the advantage arises when only global properties such as expectation values, overlaps, or samples are required.)Keywords: Linear systems, Quantum Singular Value Transformation (QSVT), Block encoding, Matrix inversion, Exponential speedup, Oracle/Query complexity.
In this demo we will restrict ourselves to matrices of size N×N, with N=2n. A generalization to arbitrary N can be done by completing the matrix into a larger one, or modifying the QSVT routine to an arbitrary N. We emphasize that compared to the basic HHL algorithm, the QSVT approach is not restricted to Hermitian matrices.The QSVT algorithm is based on the idea of block-encoding a matrix into a larger unitary:U(A,s)=(A/s∗∗∗),(1)where s is some scaling factor, which is sometimes necessary for this unitarity completion.Given an access to U(A,s), matrix inversion with QSVT implements a block-encoding for the inverse of AU(A−1,s′)=(A−1/s′∗∗∗).Subsequently, we can use this unitary to solve a linear system, A∣x⟩=∣b⟩, by applying it on an initially prepared state ∣b⟩n∣0⟩block
(the state ∣0⟩block identifies the block in which the matrix is encoded). Up to post-selection we have:U(A−1,s′)∣b⟩n∣0⟩block=s′A−1∣b⟩n∣0⟩block+ garbage.In more detail, Singular Value Decomposition (SVD) of a matrix A is defined byA=WΣV†,where W and V are unitary matrices, and Σ is a diagonal matrix that contains the singular values of A (The square root of the eigenvalues of AA†). A singular value polynomial transform refers toPoly(SV)(A)={WPoly(Σ)V†,VPoly(Σ)V†, for odd polynomial for even polynomial,where Poly(σ) is a polynomial with a well-defined parity.The QSVT routine allows to block-encode such singular value polynomial transforms, based on the Quantum Signal Processing (QSP) approach.For the case of matrix inversion, we have the identities,A†A−1=V†ΣW,=V†Σ−1W,from which we can deduce that:Applying a QSVT of an odd polynomial that approximates Poly(σ)∼1/σ, on the block-encoding of A†, gives the matrix inversion of A.Below we demonstrate how to implement a quantum linear solver for a specific problem. As we will see, the input of the algorithm is block-encoding of the matrix A, and its effective condition number (σmin/s)−1, with σmin being the minimal singular eigenvalue.Using the qsvt_inversion function from the open-library and some classical auxiliary functions from our qsp application, allow to easily implement the algorithm, given those two inputs.
We start by defining a specific problem: a matrix, its block encoding, and its condition number. We take a very simple usecase: define a random unitary of size 2n+1, taking its upper 2n×2n block as the block-encoded matrix A that we want to invert.
import numpy as npimport scipy# the size of the unitary which block encodes AREG_SIZE = 3def get_random_unitary(num_qubits, seed=4): np.random.seed(seed) X = np.random.rand(2**num_qubits, 2**num_qubits) U, s, V = np.linalg.svd(X) return U @ V.TU_a = get_random_unitary(REG_SIZE)A_dim = int(U_a.shape[0] / 2)A = U_a[:A_dim, :A_dim]print(A)
Next, we define the quantum functions required for the algortihm. It is instructive to work with a QSrtuct to represent the quantum variable for the block-encoding.
In addition, we define two quantum functions that we shall pass to the QSVT routine: a function that reflects about block at state zero, which identify the block in which the matrix is encoded, and a function that block encodes our matrix.
(Recall that for inversion we shall block-encode A†. However, the qsvt_inversion function handles this internally, by passing the inverse UA†=UA†).
As explained below, we need to evaluate an effective condition number, κ=s/min(σi) (this parameter is bounded by the actual condition number max(σi)/min(σi); see technical note at the end of this notebook).
In real life, this value is not known and needs to be approximated by some prior knowledge of the problem, or through some classical method. In our small example we will just explicitly compute the SVD decomposition of A:
svd = np.linalg.svd(A)[1]# In our simple usecase s=1s = 1kappa = s / min(svd)print(f"The effective condition number is {kappa}")
Output:
The effective condition number is 3.4598628384708703
Finding QSVT angles for the approximated inverse function
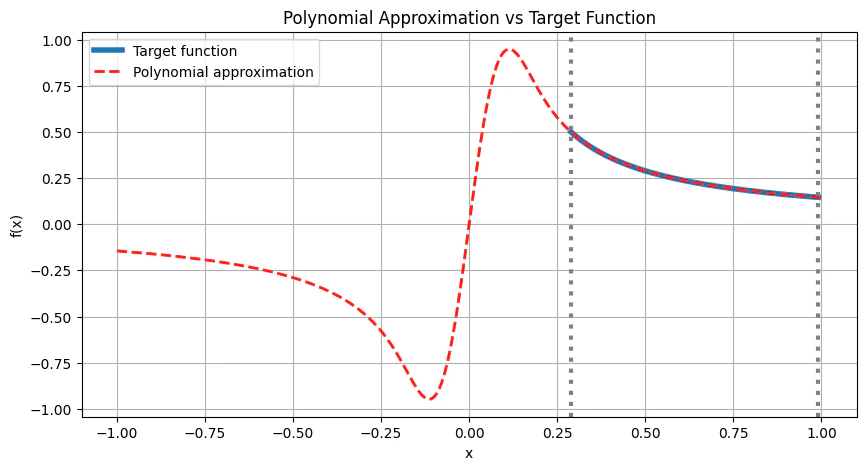
We need to find a polynomial approximation to the x1 function.Notice that the function is exploding as x goes to 0, which breaks the rules for the existence of QSP polynomial, which must be bounded by 1 in [−1,1]. However, we can limit the polynomial to approximate only at the relevant range [σmin/s,σmax/s], i.e., in the interval that contains the singular values of the block-encoded matrix.The target function we need to approximate is thus:f(x)=21κx1,x∈[σmin,σmax],where κ=s/σmin as defined below, and a scaling factor of 1/2 was added to get an easier convergence for the corresponding QSVT angles. We can see that ∣f(x)∣≤1 in the relevant range.According to Ref. [2], a degree of ∼κlog(κ/ϵ) is sufficient to approximate f(x) with an error ϵ. Below, we use the qsp_approximate function to get the approximated polynomial.This function approximates f(x) as a sum of Chebyshev polynomials, making sure the resulting polynomial is bounded by 1 in the entire range[−1,1]. Subsequently, we call the qsvt_phases to get the corresponding QSVT phases.
from classiq.applications.qsp import qsp_approximate, qsvt_phasesEPS = 1e-8degree = int(kappa * np.log(kappa / EPS))# In case we provide an even degree and ask for an odd polynimialif degree % 2 == 0: degree += 1SCALE = 0.5def target_function(x): return SCALE * 1 / (kappa * x)pcoefs, opt_res = qsp_approximate( target_function, degree=degree, parity=1, interval=[min(svd), max(svd)], plot=True)inversion_phases = qsvt_phases(pcoefs)
The interpolating function returns the coefficients, as well as the approximated maximum error between the target function and the approximating polynomial within the interval.
print( f"For the function {np.round(SCALE/kappa,5)}1/x, we approximate with an odd polynomial of degree {degree} with an error of {opt_res}")
Output:
For the function 0.144511/x, we approximate with an odd polynomial of degree 69 with an error of 4.707465528497323e-09
Let us synthesize, visualize, and execute.For the execution, we choose a statevector simulator, as we are considering a small problem for demonstrating the algorithm. In addition, later on we would like to verify our result against the expected classical one.
qprog = synthesize(main)show(qprog)execution_preferences = ExecutionPreferences( num_shots=1, backend_preferences=ClassiqBackendPreferences( backend_name=ClassiqSimulatorBackendNames.SIMULATOR_STATEVECTOR ),)with ExecutionSession(qprog, execution_preferences) as es: # Currently, filtering is possible for QBit and QNum, but not for QStruct es.set_measured_state_filter("qsvt_aux", lambda state: state == 0.0) result = es.sample()
Output:
Quantum program link: https://platform.classiq.io/circuit/35YjqMigetKATtz2myYGsDMwvie
If our matrix A is block-encoded with a block variable of size m, then the QSVT routine block encodes the inverse of A on m+1 qubits, where the additional qubit is the qsvt_aux. Therefore, we need to post-select on qsvt_state.block and qsvt_aux being zero, if we want to obtain a state ∼A−1∣b⟩.Note that the additional block qubit was already filtered as part of the execution call.
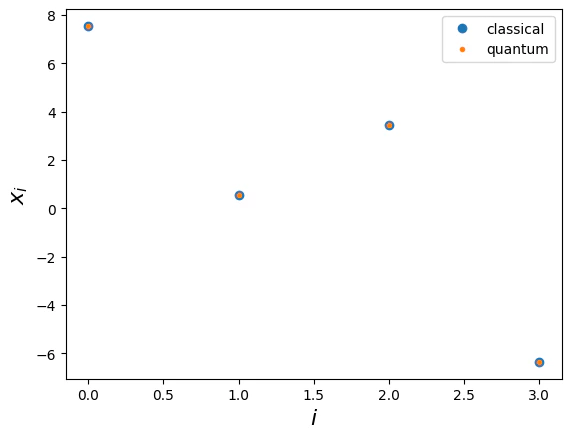
Finally, we verify our quantum solution, by comparing it to the expected classical one.
expected_x = np.linalg.inv(A) @ b
The quantum routine returns,∣x⟩=κ(scale)(A/s)−1∣b∣b∣0⟩block∣0⟩aux+grabage,after post-selection (statevector filtering) for the block, we have:x=κ(scale)(A/s)−1∣b∣b,where in our specific usecase we have scale=0.5 and s=1. We can now collect all the prefactors and compare to the expected result.
Let’s compare it with the expected solution:Comment: even after removing the global phase to ensure a real solution, the quantum solution can be obtained up to a sign.
import matplotlib.pyplot as pltplt.plot(expected_x, "o", label="classical")plt.plot(computed_x, ".", label="quantum")plt.xlabel(r"$i$", fontsize=16)plt.ylabel(r"$x_i$", fontsize=16)plt.legend();
A note on efficient block-encoding, condition number, and complexity
An efficient block-encoding of a matrix A means that the resources to construct the unitary UA,s, as well as the scaling factor s, scales poly-logarithmically with the matrix dimension.This technical note concerns the latter point.First, we note that an optimal value for the scaling factor s is the maximal singular value σmax, namely s≥σmax.This comes directly from the requirement that ∣∣A/s∣∣≤1.For that reason, the effective condition number used throughout the demo, κ=s/σmin, is bounded from below by the actual condition number σmax/σmin.Next, note that if s scales linearly with the problem size, then the exponential speedup is lost.This is because the polynomial degree then scales as O(N). In addition, the amplitude of the encoded solution scales the same (although it also depends on the input vector ∣b⟩), which requires an additional amplitude amplification routine that adds a factor of O(N) to the overall resources.