View on GitHub
Open this notebook in GitHub to run it yourself
- Input: A matrix and a known vector .
- Output: An approximation of a normalized solution proportional to , satisfying the equation .
While the output of VQLS mirrors that of the HHL Quantum Linear-Solving Algorithm, VQLS distinguishes itself by its ability to operate on Noisy Intermediate-Scale Quantum (NISQ) computers. In contrast, HHL necessitates more robust quantum hardware and a larger qubit count, despite offering a faster computation speedup. This tutorial covers an implementation example of a Variational Quantum Linear Solver [1] using block encoding. In particular, we use linear combinations of unitaries (LCUs) for the block encoding. As with all variational algorithms, the VQLS is a hybrid algorithm in which we apply a classical optimization on the results of a parametrized (ansatz) quantum program.
Building the Algorithm with Classiq
Quantum Part: Variational Circuit
Given a block encoding of the matrix A: we can prepare the state We can approximate the solution with a variational quantum circuit, i.e., a unitary circuit , depending on a finite number of classical real parameters : Our objective is to address the task of preparing a quantum state such that is proportional to ; or, equivalently, ensuring that The state arises from a unitary operation applied to the ground state of qubits; i.e., To maximize the overlap between the quantum states and , we optimize the parameters, defining a cost function: At a high level, the above could be implemented as follows: We construct a quantum model as depicted in the figure below. When measuring the circuit in the computational basis, the probability of finding the system qubits in the ground state (given the ancillary qubits measured in their ground state) is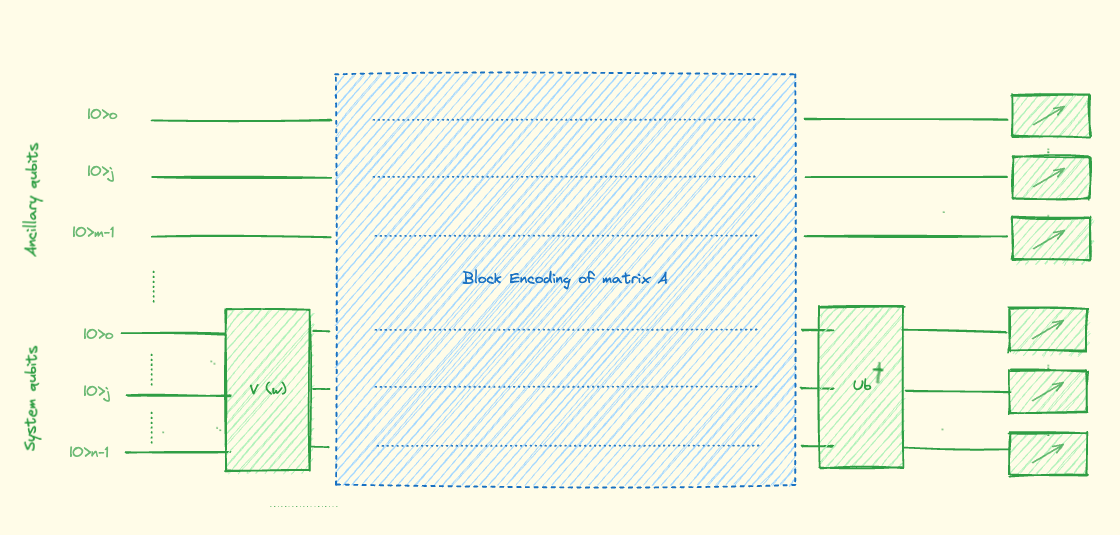
block_encoding_vqls function as follows:
ansatz, block_encoding, and prepare_b_state to fit the specific example above.
Now we are ready to build our model, synthesize it, execute it, and analyze the results.
Classical Part: Finding Optimal Parameters
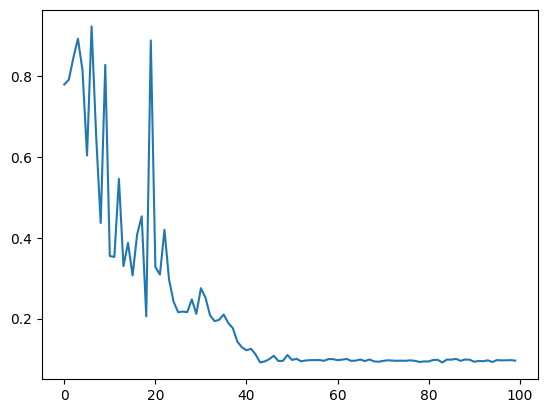
To estimate the overlap of the ground state with the post-selected state, we could directly make use of the measurement samples. However, since we want to optimize the cost function, it is useful to express everything in terms of expectation values through Bayes’ theorem: To evaluate the conditional probability from the above equation, we construct the following utility function to operate on the measurement results: To variationally solve our linear problem, we define the cost function that we are going to minimize. As explained above, we express it in terms of expectation values through Bayes’ theorem. We define a classical function that gets the quantum program, minimizes the cost function using the COBYLA optimizer, and returns the optimal parameters.Once the optimal variational weights
w are found, we
can generate the quantum state . By measuring in
the computational basis we can estimate the probability of each basis
state.
Example Using LCU Block Encoding
We treat a specific example based on a system of three qubits: where represent the Pauli , Pauli , and Hadamard gates applied to the qubit with index . To block encode the matrix A we use the LCU method. This can be done with thelcu_paulis library function.
Note that this function can get a unnormalized Pauli operator, thus we calculate the normalization factor for the post-process analysis.
The LCU quantum circuit looks as follows:
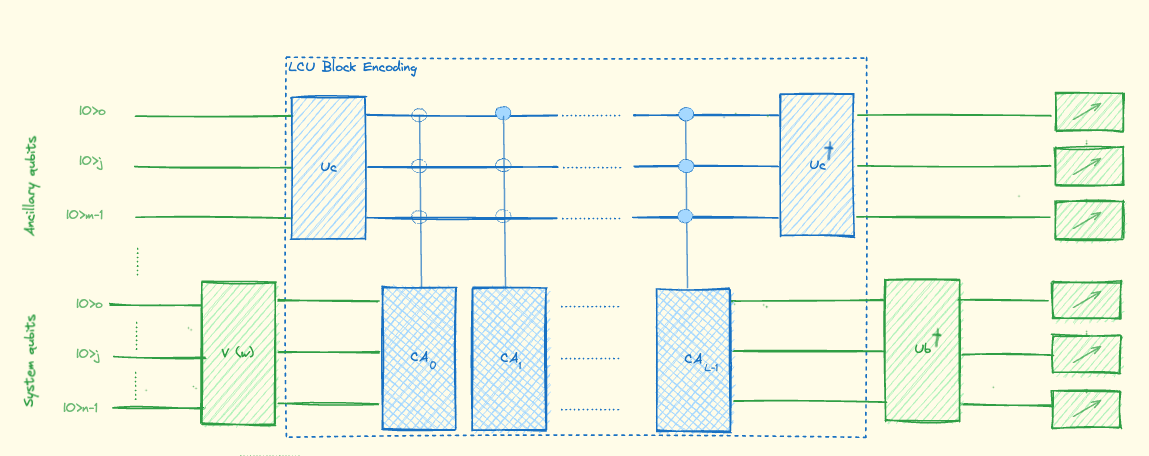
Fixed Hardware Ansatz
Let’s consider our ansatz , such that This allows us to “search” the state space by varying a set of parameters, . The ansatz that we use for this three-qubit system implementation takes in nine parameters as defined in theapply_fixed_3_qubit_system_ansatz function:
Output:

Running the VQLS
Now, we can define the main function: we callblock_encoding_vqls with the arguments of our specific example.
Output:

Output:
Measuring the Quantum Solution
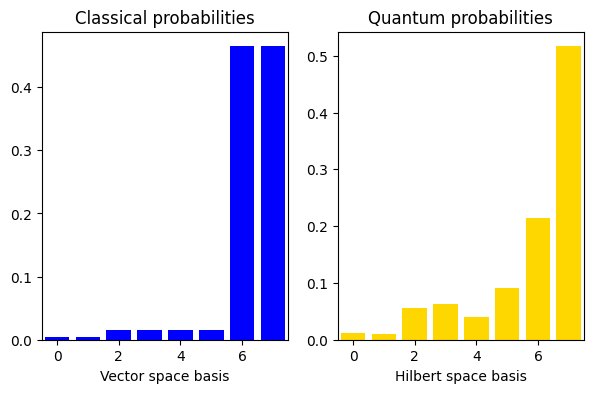
Finally, we can apply the optimal parameters to measure the quantum results for :Output:
Comparing to the Classical Solution
Since the specific problem considered in this tutorial has a small size, we can also solve it in a classical way and then compare the results with our quantum solution. We use the explicit matrix representation in terms of numerical NumPy arrays. Classical calculation:Output:
Output: