

View on GitHub
Open this notebook in GitHub to run it yourself
max-LINSAT Problem
- Input: A matrix and functions for , where is a finite field.
- Output: a vector that best maximizes .
max-XORSAT Problem
- Input: A matrix and a vector with .
- Output: a vector that best maximizes .
Algorithm Description
The strategy is to prepare this state: where is a normalized polynomial. Choosing a good polynomial can bias the sampling of the state towards high values. The higher the degree of the polynomial, the better approximation ratio of the optimum we can get. The Hadamard spectrum of is where are normalized weights that can be calculated from the coefficients of . So, to prepare , we prepare its Hadamard transform, then apply the Hadamard transform over it. Stages:- Prepare .
- Translate the binary encoded to a unary encoded state , resulting in the state .
- Translate each to a Dicke state [2], resulting in the state .
- For each , calculate , getting .
- Uncompute by decoding .
- Apply the Hadamard transform to get the desired .
x with high values with high probability (see the last plot in this notebook).

- The full DQI circuit for a MaxCut problem.
x solutions are sampled from the target variable after the last Hadamard transform.*
Defining the Algorithm Building Blocks
Next, we define the needed building-blocks for all algorithm stages. Step 1 is omitted as we use the built-inprepare_amplitudes function.
Step 2: Encoding Conversions
We use three different encodings:- Binary encoding: Represents a number using binary bits, where each qubit corresponds to a binary place value.
- One-hot encoding: Represents a number by activating a single qubit, with its position indicating the value.
- Unary encoding: Represents a number by setting the first qubits to 1 is the number, and the rest to
- For example, the number 3 on 4 qubits is .
QNum) to one-hot encoding, and show how to convert the one-hot encoding to a unary encoding.
The conversions are done in place, meaning that the same binary encoded quantum variable is extended to represent the target encoding.
We use the library function binary_to_unary, based on this post. Let’s test the conversion of the number 8 from binary to unary:
| one_hot | count | probability | bitstring | |
|---|---|---|---|---|
| 0 | [1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0] | 2048 | 1.0 | 000000011111111 |
Step 3: Dicke State Preparation
We transform a unary input quantum variable to a Dicke state, such that We use the library functionprepare_dicke_state, with a recursive implementation that is based on [2].
The recursion works bit by bit.
We test the function for the Dicke state of 6 qubits with 4 ones:
| qvar | count | probability | bitstring | |
|---|---|---|---|---|
| 0 | [1, 1, 0, 0, 1, 1] | 161 | 0.078613 | 110011 |
| 1 | [1, 1, 0, 1, 1, 0] | 155 | 0.075684 | 011011 |
| 2 | [1, 0, 1, 1, 1, 0] | 153 | 0.074707 | 011101 |
| 3 | [0, 1, 1, 1, 1, 0] | 144 | 0.070312 | 011110 |
| 4 | [0, 0, 1, 1, 1, 1] | 142 | 0.069336 | 111100 |
| 5 | [0, 1, 1, 0, 1, 1] | 139 | 0.067871 | 110110 |
| 6 | [1, 0, 1, 0, 1, 1] | 138 | 0.067383 | 110101 |
prepare_dicke_state_unary_input, which is actually a subrutine of prepare_dicke_state:
| qvar | count | probability | bitstring | |
|---|---|---|---|---|
| 0 | [1, 0, 0, 1, 0, 0] | 156 | 0.076172 | 001001 |
| 1 | [0, 0, 1, 0, 1, 0] | 153 | 0.074707 | 010100 |
| 2 | [1, 0, 0, 0, 0, 1] | 147 | 0.071777 | 100001 |
| 3 | [0, 0, 0, 0, 1, 1] | 147 | 0.071777 | 110000 |
| 4 | [1, 1, 0, 0, 0, 0] | 143 | 0.069824 | 000011 |
| 5 | [0, 0, 1, 1, 0, 0] | 142 | 0.069336 | 001100 |
| 6 | [0, 0, 0, 1, 0, 1] | 142 | 0.069336 | 101000 |
Step 4: Vector and Matrix Products
Define a matrix and vector product over the binary field functions:Assembling the Full max-XORSAT Algorithm
Here, we combine all the building blocks into the full algorithm. To save qubits, the decoding is done in place, directly onto the register. The only remaining part is the decoding, that will be treated after choosing the problem to optimize, as it depends on the input structure.dqi_max_xor_sat is the main quantum function of the algorithm. It expects the following arguments:
B: the (classical) constraints matrix of the optimization problemv: the (classical) constraints vector of the optimization problemw_k: a (classical) vector of coefficients corresponding to the polynomial transformation of the target function.
y: the (quantum) array of the errors for the decoder to decode. If the decoder is perfect, it should hold only zeros at the outputsolution: the (quantum) output array of the solution. It holds before the Hadamard transform.syndrome_decode: a quantum callable that accepts a syndrome quantum array and outputs the decoded error on its second quantum argument
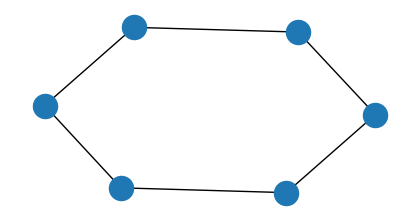
Example Problem: Max-Cut for Regular Graphs
Now, let’s be more specific and optimize a Max-Cut problem. We choose specific parameters so that with the resulting matrix we can decode up to two errors on the vector . The translation between Max-Cut and max-XORSAT is quite straightforward. Every edge is a row, with the nodes as columns. The vector is all ones, so that if , we get a constraint , which is satisfied if , are on different sides of the cut.Output:
Original Sampling Statistics
Let’s plot the statistics of for uniformly sampling , as a histogram. Later, we show how to get a better histogram after sampling from the state of the DQI algorithm.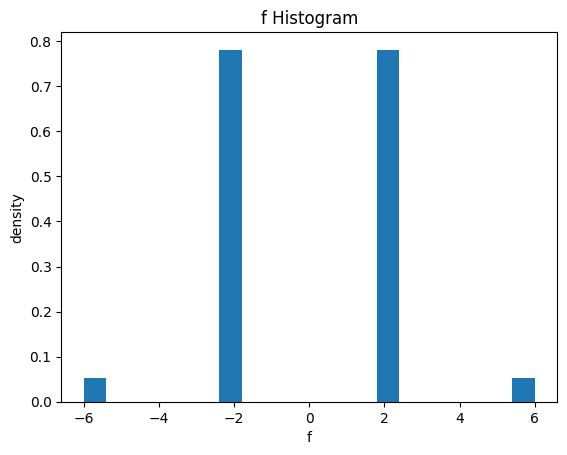
Decodability of the Resulting Matrix
The transposed matrix of the specific matrix we have chosen can be decoded with up to two errors, which corresponds to a polynomial transformation of of degree 2 in the amplitude, and degree 4 in the sampling probability:Output:
Step 5: Defining the Decoder
For this basic demonstration, we use a brute force decoder that uses a lookup table for decoding each syndrome in superposition:Choosing Optimal Coefficients
According to the paper [1], this is done by finding the principal value of a tridiagonal matrix defined by the following code. The optimality is with regard to the expected ratio of satisfied constraints.Output:
Synthesis and Execution of the Full Algorithm
Output:
| y | solution | count | probability | bitstring | |
|---|---|---|---|---|---|
| 0 | [0, 0, 0, 0, 0, 0] | [0, 1, 0, 1, 1, 0] | 2966 | 0.2966 | 011010000000 |
| 1 | [0, 0, 0, 0, 0, 0] | [1, 0, 1, 0, 0, 1] | 2893 | 0.2893 | 100101000000 |
| 2 | [0, 0, 0, 0, 0, 0] | [0, 1, 1, 0, 1, 0] | 138 | 0.0138 | 010110000000 |
| 3 | [0, 0, 0, 0, 0, 0] | [0, 1, 0, 0, 1, 0] | 136 | 0.0136 | 010010000000 |
| 4 | [0, 0, 0, 0, 0, 0] | [1, 0, 0, 1, 0, 1] | 136 | 0.0136 | 101001000000 |
| … | … | … | … | … | … |
| 59 | [0, 0, 0, 0, 0, 0] | [1, 0, 0, 0, 1, 0] | 8 | 0.0008 | 010001000000 |
| 60 | [0, 0, 0, 0, 0, 0] | [1, 0, 0, 0, 1, 1] | 8 | 0.0008 | 110001000000 |
| 61 | [0, 0, 0, 0, 0, 0] | [0, 1, 1, 1, 1, 1] | 8 | 0.0008 | 111110000000 |
| 62 | [0, 0, 0, 0, 0, 0] | [0, 0, 0, 1, 0, 1] | 7 | 0.0007 | 101000000000 |
| 63 | [0, 0, 0, 0, 0, 0] | [1, 0, 0, 1, 1, 1] | 7 | 0.0007 | 111001000000 |
64 rows × 5 columns
y variable correctly:
y vector is indeed clean.
Postprocessing
Finally, we plot the histogram of the sampled values from the algorithm, and compare it to a uniform sampling of values, and also to sampling weighted by and values. We can see that the DQI histogram is biased to higher values compared to the other sampling methods.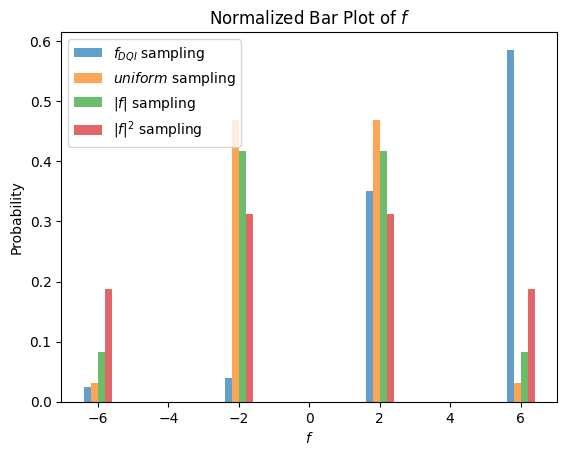
Output: